
Understanding and Using the Meaning Extraction Method
Most text analysis methods can be classified as working in either a "top-down" or "bottom-up" fashion. Top-down methods, like LIWC, start with a pre-defined set of words that researchers are "looking for" that they know (or strongly believe) to be related to important psychological processes. Popular top-down methods range from dictionary-based approaches to the most sophisticated supervised learning algorithms in the natural language processing world.
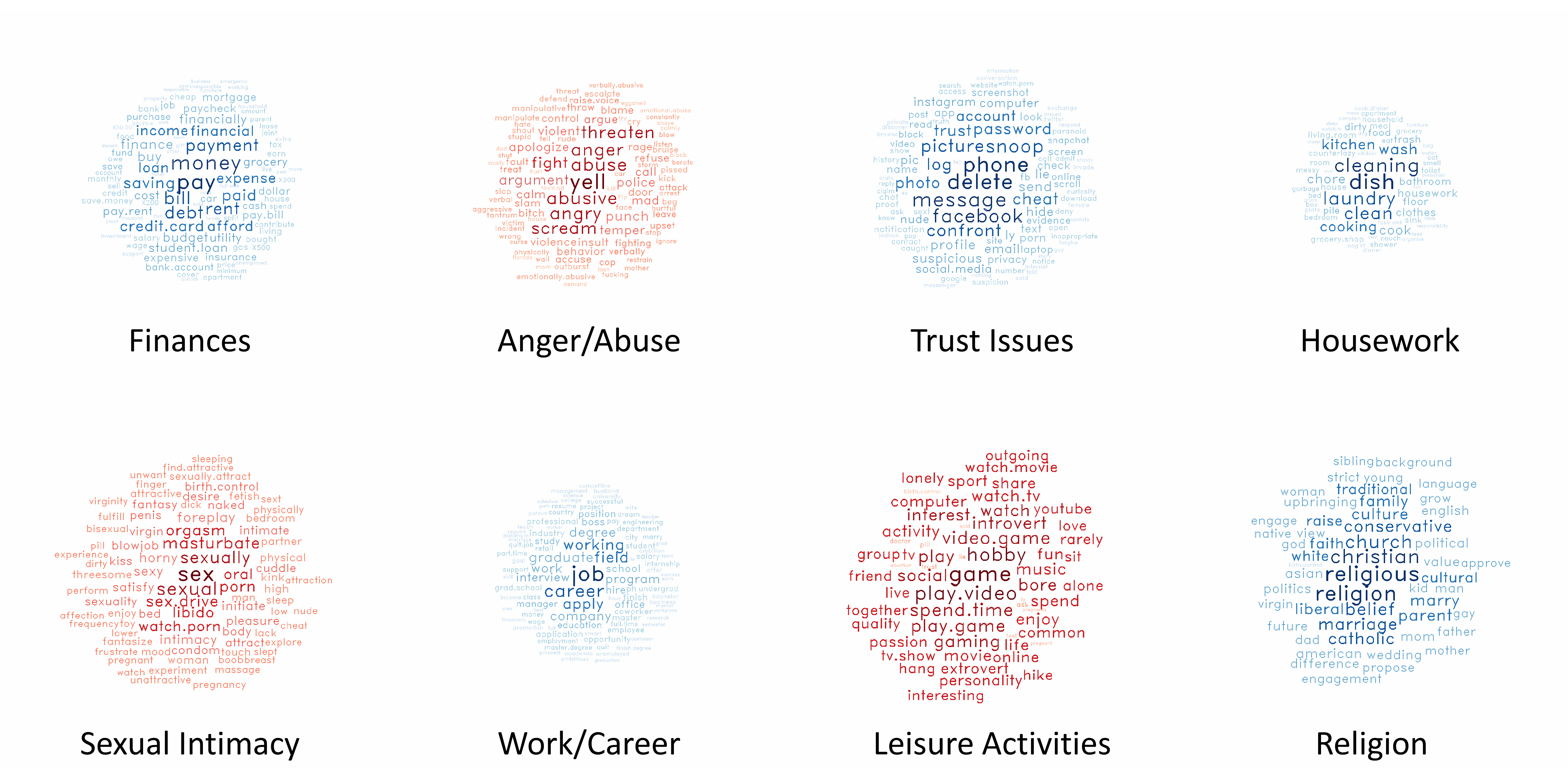
However, you may find yourself wanting to understand what people are talking about in your dataset. What are are the common "themes" or "topics" that are being discussed within your sample? This is where bottom-up methods come in handy: in particular, a family of methods commonly referred to as "topic modeling." For example, Entwistle et al. (2021) were looking to understand what types of relationship problems people commonly mentioned online. Using a topic modeling procedure known as the Meaning Extraction Method, they found that people who were sharing their relationship problems online commonly talking about things like money, physical intimacy, and leisure activities:
Originally created by Chung and Pennebaker (2008), the Meaning Extraction Method (MEM) is one of many topic modeling approaches that can be found in the text analysis world. What is unique about the MEM approach, however, is that it originates from psychometric theory and statistical procedures that are common in the social sciences. The MEM has evolved over time and involves a handful of steps to get from text to extracting themes. This page will guide you through the basics of the MEM. Before starting, however, we strongly recommend checking out the references below and elsewhere to gain a more nuanced understanding of how the MEM can be used. In particular, we recommend starting with Boyd (2017) as a basic MEM primer.
How the MEM Works
The basic process of the MEM is fairly straight-forward:
- Convert words to their simplest form (e.g., run, running, and ran all become the word run)
- Scan your dataset to figure out which words are the most common across all texts
- Create a "document-term matrix" from your dataset — that is, a table that shows which texts contain which common words
- Perform a Principal Components Analysis with varimax rotation (or other reduction method of your choice) on the document-term matrix
Currently, the Meaning Extraction module in LIWC-22 will do Steps 1-3 for you. Future updates of LIWC-22 may include Step 4 as well (stay tuned!). Put another way: given a good-sized sample of texts, LIWC-22 will convert this into a document-term matrix that you can then analyze to extract themes in your favorite statistical software, such as R, Python, or SPSS.
Performing the MEM
The meaning extraction method, like all topic modelling methods, is not as straight-forward as something like a traditional LIWC analysis. There are several decisions that you will need to make as you are running the MEM — things like the minimum word count for text inclusion, the specific words that you would like to omit (i.e., the "stop list"), and so on — that take a bit of time and practice to learn. The way in which you make these decisions will depend on a lot of things: the size of your dataset, the typical length of each text, and the nature/origin of the texts themselves.
There are no hard-and-fast rules for the MEM, which can also cause some stress in people who need clear rules to follow for any time of analysis. Take our advice: kick back, relax, and go with the (analytic) flow — with a bit of practice, you'll learn what works best with the type of data that you typically analyze. While it can feel a bit daunting to newcomers, trust us when we say that it will rapidly become second nature — it just takes a little bit of practice 😊
Dataset
Like the other parts of LIWC-22, the first thing that you will want to do is select your dataset. Unlike "top-down" text analysis methods like LIWC, topic models typically work better when you have more data: both in terms of the number of texts, but also in terms of the length of each text. How much text is enough? Like most things in the bottom-up text analysis world, the answer to most questions is "it depends." In general, you can have a smaller number of long texts (e.g., 100 to 200 texts at about 500-1,000 words each), or a really large number of short texts (e.g., 10,000+ texts that are only a sentence or two long, such as tweets). But, in both cases, more is virtually always better, especially if the texts are all dealing with completely different content.
N-Gram Settings
N-grams refer to phrases of "N" length. For example, "happy" is a 1-gram, "very happy" is a 2-gram, and so on. In LIWC-22, you can extract up to 3-grams for your meaning extraction analyses. Note that, due to the statistical properties of language, higher values for N will take exponentially more time/memory to run. In 99% of cases, we recommend simply sticking with 1-grams.
Skip texts with Word Count < ...
Because the meaning extraction method operates by analyzing word co-occurrences, extremely short texts have a tendency to add a lot of noise to our results. This is because a text with only two words ("I'm" and "hungry") does not provide a lot of information about how words tend to be used. Two words co-occur and all other words do not. In general, we recommend omitting texts with fewer than 10 words. If you are working with longer texts, you should consider setting this threshold higher (e.g., 100 words or even 1,000 words).
Omit Words
Topic models generally work by finding clusters of words that have some type of shared meaning. However, a large class of words called "function words" generally do not have any meaning in and of themselves and, thus, we want to omit them from our MEM analysis. Additionally, you may find that some words in your dataset occur at high frequency due to contextual factors. For example, an MEM of dream reports might find that the words "dream" and "woke" occur at very high rates; this is the result of people starting off their dream reports with phrases like "In my dream last night..." and "...and then I woke up." In such cases, you will typically also want to omit words that do not contribute to an understanding of the specific topics being discussed in your texts.
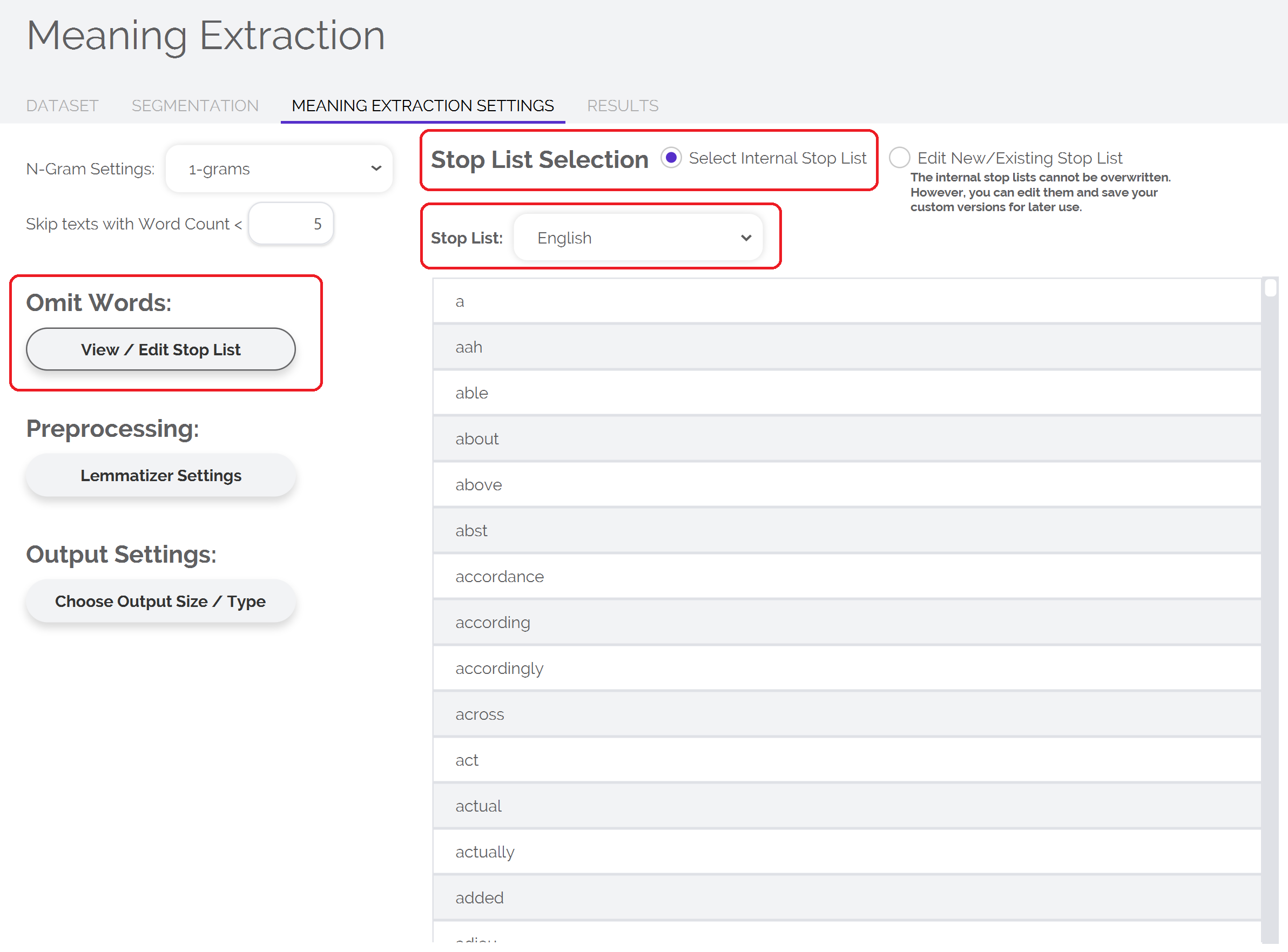
Words that are filtered out during text analyses are called "stop words" — a list of stop words, then, is known as a "stop list." LIWC-22 comes with a few prebuilt stop lists built in that you can use to save some time and avoid having to build your own. To load a prebuilt stop list in LIWC-22:
- Click the "View / Edit Stop List" button
- Ensure that "Select Internal Stop List" is selected
- Select which prebuilt stop list you would like to use from the dropdown menu
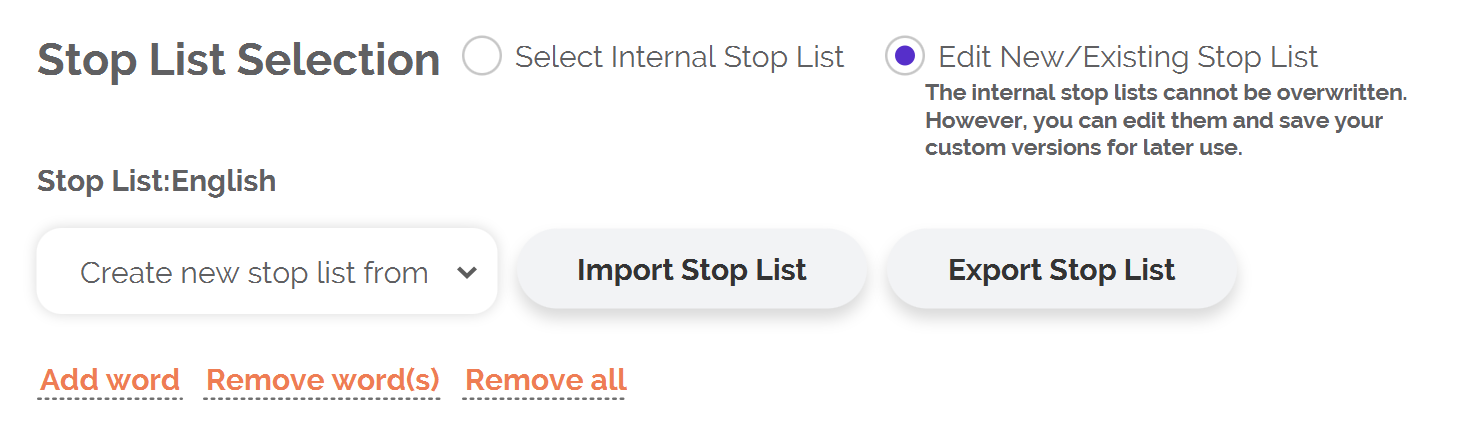
However, the specific words that you include in your stop list will vary as a function of your own research needs, the nature of your dataset, and so on. To create your own custom stop list, select the "Edit New/Existing Stop List" option. From this menu, you can create a new stop list based on one of the prebuilt stop lists, or you can start from scratch. Additionally, you can export your stop list to a .txt file, making it easy to reuse your stop list later or share your stop list with other researchers.
Note: If you have a stop list of your own that you would like to have included in LIWC-22 for other researchers to use by default, please send us an e-mail to discuss.
Preprocessing
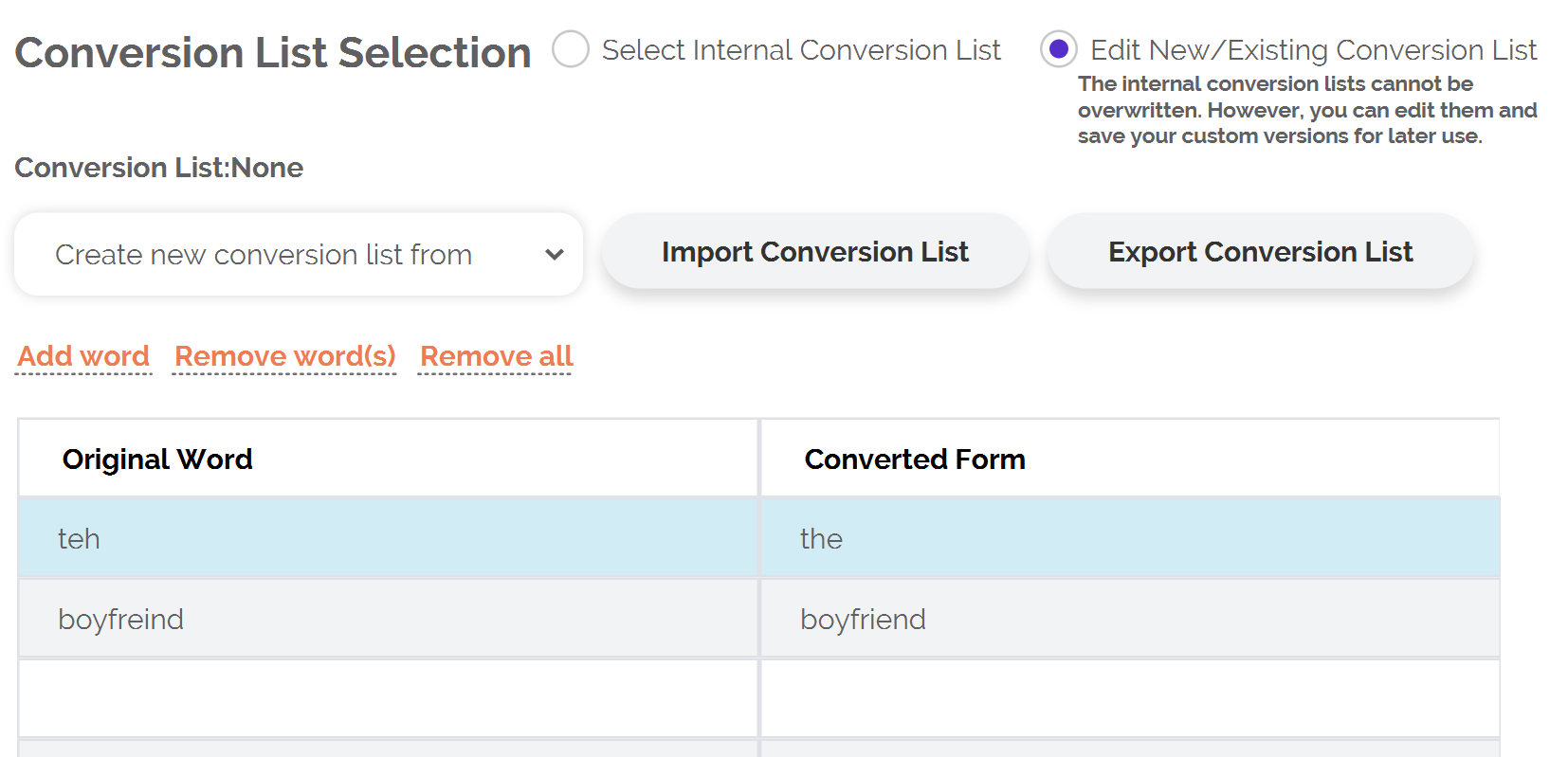
Most natural language processing methods involve some amount of "preprocessing" — that is, some "cleaning" and adjustments that are applied to your text before you begin the more formal analysis that you're planning to conduct. An extremely useful part of text preprocessing involves adjusting the forms in which words occur across a collection of texts. Sometimes this involves standardizing the spelling of a word (e.g., "color" versus "colour"), fixing spelling errors ("boyfreind" instead of "boyfriend"), and so on. For the MEM, a helpful part of this preprocessing is "lemmatization" — the conversion of words to their simplest forms. Lemmatization can be done in many ways, ranging from very sophisticated and elegant machine learning methods to simple "find and replace" procedures. LIWC-22 opts for the simpler approach, increasing transparency and allowing users to customize their list of words to adjust during preprocessing.
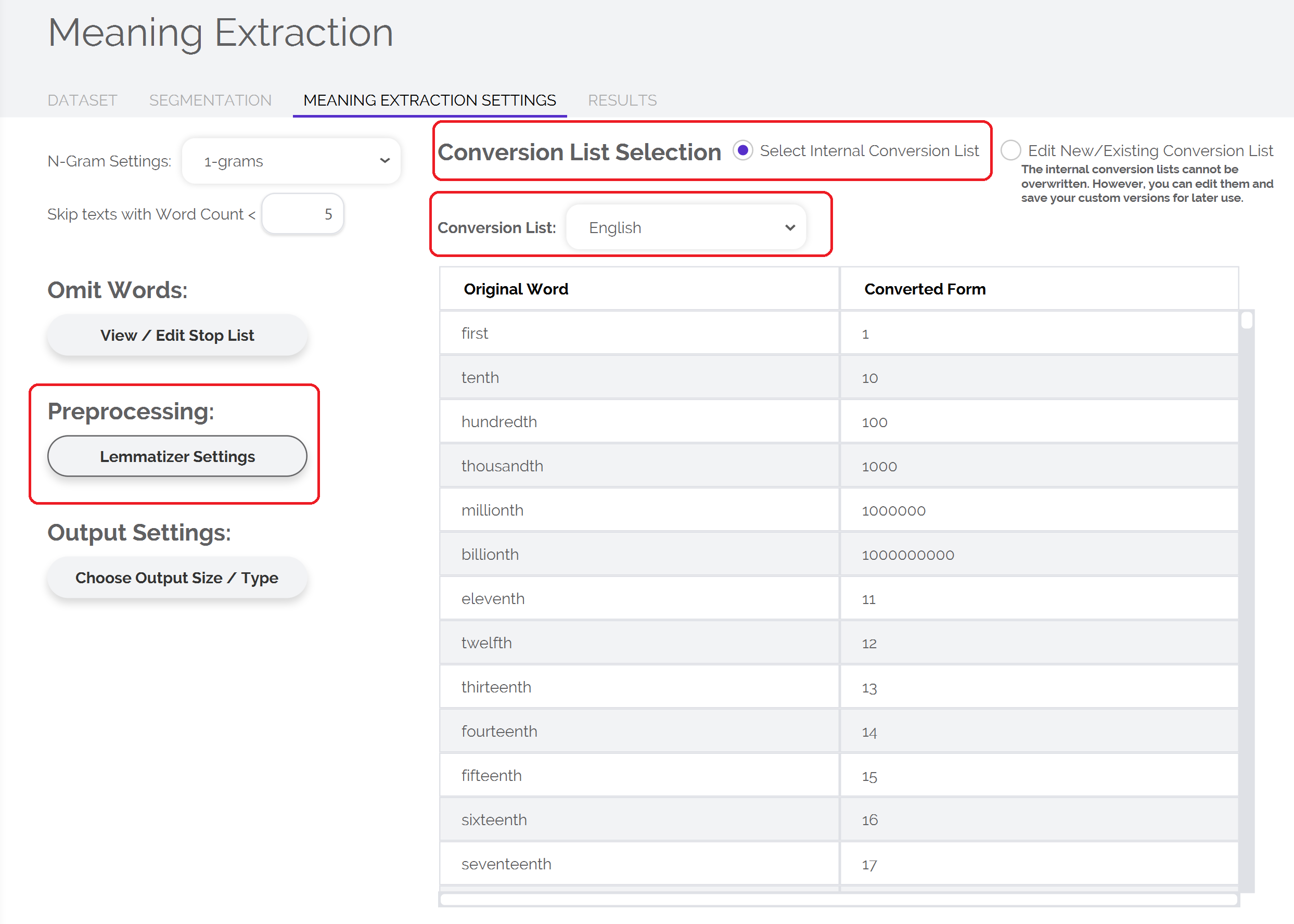
To select/modify your conversion list:
- Select the "Lemmatizer Settings" option
- Choose to use a prebuilt conversion list or, alternatively, you can choose to create your own
- If using a prebuilt conversion list, choose which list you would like to use from the dropdown menu
As with the stop list features described above, you can import/export your own custom conversion lists to share with others or use later for your own research.
Output Settings: Output Type
When you are building your dataset that shows which texts contain which words (i.e., your document-term matrix, or DTM), there are several scoring systems that you may choose to use. For example, you might want to know in a binary, "yes or no?" fashion whether a word appears in a text. Alternatively, you might want to know how many times each word appears in each text. There are different types of output that LIWC-22 can generate for your DTM, each with its own common uses:
- Binary Output (also known as "one-hot" encoding). This output format simply reflects whether a given text does or does not contain each word using 1's and 0's, respectively. This is the most commonly-used form of output for the MEM and works best when you have relatively short texts (< ~250 words). Highly recommended for very short texts, such as tweets or other social media posts.
- Relative frequencies. This output format reflects what percentage of words in each text is accounted for by each specific word. For example, in the sentence "I think this is the beginning of a beautiful friendship," the word "friendship" accounts for 10% of the words. Relative frequencies are usually best used when you have a modest sample size with medium-length texts (e.g., 500 to 1,000 words). Additionally, this output format can be helpful for analyzing very long texts, or samples with texts that do not have a uniform word count.
- Raw Counts. This output type reflects the total number of times each word appears in each text. This output format is quite versatile, and is also what is most often used for other forms of topic models, such as Latent Dirichlet Allocation.
As with everything else in the MEM, the "best" output format for your research will depend on a confluence of several factors. We recommend experimenting with different output types to see which provides the most intuitive results with your dataset.
You can perform a topic modeling procedure on your DTM regardless of which output type you use. For the meaning extraction method, you simply conduct a Principal Components Analysis with varimax rotation on your DTM and then, voila!
Output Settings: Output Size
Last but not least, there are some considerations as to which words we want to include in our document-term matrix (DTM). While an in-depth discussion of word frequency statistics is beyond the scope of this page, it is helpful to understand that most words in any language have a very low frequency. For statistical modeling (and thus, topic modeling) purposes, we generally only care about capturing variations in (relatively) common words that are used by at least a minimum number (or percent) of observations in our sample — we can then discard all other words.
There are no hard-and-fast rules for choosing which words to include and which to omit from our DTM, however, LIWC-22 provides a few options for choosing which words to retain based on the distribution of words in your dataset. These options are as follows:
- Retain N-grams that appear in >= % of Documents. This option will ensure that your final output only includes N-grams that appeared at least once in X% of all documents. This is the most common setting used by social scientists to ensure that the only words included in their DTM are those used by a bare minimum percentage of their sample. The percentage that you use as your X value will depend greatly on the size of texts within your sample. If you are analyzing medium-to-long texts (e.g., > 250 words), you may use something like 5-10% as your X value. If analyzing short texts, such as tweets or forum posts, you may need to set this parameter much lower, such as 0.10%.
- Retain N-grams with Raw Frequency >= X. This option retains N-grams that occur at least X times in your dataset.
- Retain the X most Frequent N-grams (by Raw Frequency). This option will retain the ~X most frequency N-grams in your dataset (e.g., 500). The decision for which N-grams to keep is based on the raw frequency of each N-gram.
- Retain the X most Frequent N-grams (by % Documents). Same as the previous option, but instead of retaining N-grams as a function of their raw frequency, LIWC-22 will retain the ~X most frequent words in your dataset based on the the percent of documents that each N-gram occurs in.
Segmentation
For topic modeling, segmentation is often used to squeeze more mileage out of your dataset. For longer texts (especially things like books, speeches, etc.), you may not want to look for word co-occurrence patterns at the full-text level. There are a lot of considerations to take here, but the big one is the typical length of each text within your dataset (depending on your other settings/approaches to the MEM).
If you are working with particularly long texts, you might want to segment them such that each chunk of text is no longer than ~250 words or so. If you want to really maximize the amount of data that you can get from your dataset, you can segment your texts using a regular expression to split texts into (approximately) individual sentences:
(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?|\!)\s
Note, however, that in many (or perhaps most) user's cases, you might not need to segment your texts at all. We recommend avoiding segmentation unless you have a good rationale for doing so.
References and Further Reading
- Blackburn, K. G., Hontanosas, J., Nahas, K., Bajaj, K., Thompson, R., Monaco, A., Campos, Y., Tran, T., Obregon, S., & Wetchler, E. (2020). Food foraging online: Exploring how we choose which recipes to search and share. First Monday. https://doi.org/10.5210/fm.v25i12.10863
- Boyd, R. L. (2017). Psychological text analysis in the digital humanities. In S. Hai-Jew (Ed.), Data Analytics in Digital Humanities (pp. 161–189). Springer International Publishing. https://doi.org/10.1007/978-3-319-54499-1_7
- Chung, C. K., & Pennebaker, J. W. (2008). Revealing dimensions of thinking in open-ended self-descriptions: An automated meaning extraction method for natural language. Journal of Research in Personality, 42(1), 96–132. https://doi.org/10.1016/j.jrp.2007.04.006
- Entwistle, C., Horn, A. B., Meier, T., & Boyd, R. L. (2021). Dirty laundry: The nature and substance of seeking relationship help from strangers online. Journal of Social and Personal Relationships, 38(12), 3472–3496. https://doi.org/10.1177/02654075211046635
- Fitzpatrick, M. R., & Armstrong, C. R. (2010). Beyond the tip of the iceberg: Exploring the potential of the meaning extraction method and aftercare e-mail themes. Psychotherapy Research, 20(1), 86–89. https://doi.org/10.1080/10503300903352719
- González, F., Yu, Y., Figueroa, A., López, C., & Aragon, C. (2019). Global reactions to the Cambridge Analytica scandal: A cross-language social media study. Companion Proceedings of The 2019 World Wide Web Conference, 799–806. https://doi.org/10.1145/3308560.3316456
- Markowitz, D. M. (2021). The meaning extraction method: An approach to evaluate content patterns from large-scale language data. Frontiers in Communication, 6. https://doi.org/10.3389/fcomm.2021.588823
- Pérez-Rosas, V., Mihalcea, R., Resnicow, K., Singh, S., & An, L. (2017). Understanding and predicting empathic behavior in counseling therapy. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1426–1435. https://doi.org/10.18653/v1/P17-1131
- Stanton, A. M., Boyd, R. L., Pulverman, C. S., & Meston, C. M. (2015). Determining women’s sexual self-schemas through advanced computerized text analysis. Child Abuse and Neglect, 46. https://doi.org/10.1016/j.chiabu.2015.06.003