
Understanding and Using LSM
Language Style Matching (LSM) is a metric that measures the degree two or more text samples match in their writing styles. The text samples could refer to a transcript of two people in a conversation, a comparison of the language of emails among people in a business, or even the language of an entire subreddit community. LSM is measured by calculating people’s similarity in the use of function words (e.g., articles, prepositions, conjunctions, and so on).
Below is the formula for calculating LSM for any one of the function categories. The relative similarity in use of function words between two or more people is calculated for each person category of language separately, then averaged to create a composite measure of LSM. The 0.0001 in the denominator is there to prevent dividing by zero in the rare cases that a dyad uses no function words in a particular category.
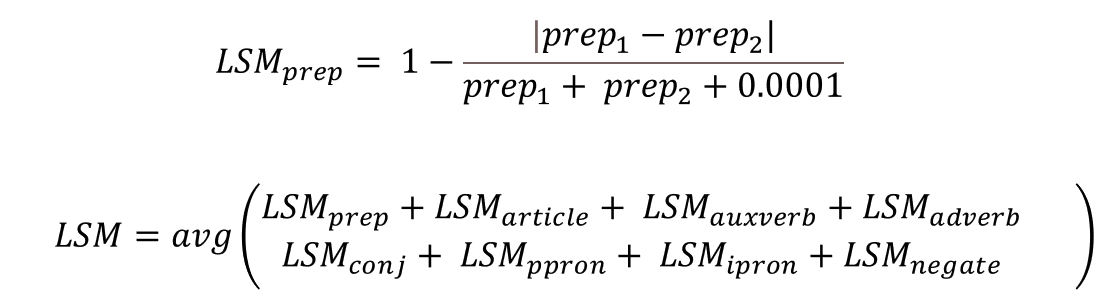
Understanding Which "Type" of LSM to Use
One of the more confusing parts of LSM is that, despite the simplicity of the formula above, there are many ways that LSM can be calculated. What if you have a group of 5 people? Do you calculate LSM between each pairwise combination of people, and then average it? Or, instead, do you calculate LSM between each person and the "average" language of the rest of the group? These are not easy questions to answer, and different researchers will have different needs based on the precise nature of their research question.
Thankfully, LIWC-22 can provide you with output for LSM that has been calculated in a few different ways. For a simple reference to help you understand your options, please explore the following table:
| LSM Results Options | When to Use | Person-Level | Group-Level | Example |
|---|---|---|---|---|
| Pairwise Comparison | Use when interested in relationships between individual people within a group | LSM is calculated between each dyadic pair of individuals within each group | The Person-Level scores are calculated, but the output only provides the Group-Level average | Person 1 vs. Person 2 Person 1 vs. Person 3 Person 2 vs. Person 3 |
| One-to-Many Comparison | Use when interested in the fit of each person within the whole group | LSM is calculated between each person and the combined (i.e., weighted average) language of the rest of the group members | The Person-Level scores are calculated, but the output only provides the Group-Level average | P1 vs. Avg(P2, P3) P2 vs. Avg(P1, P3) P3 vs. Avg(P1, P2) |
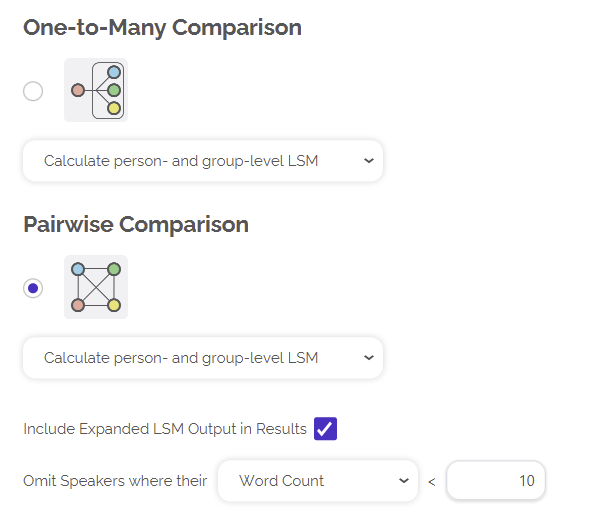
For the output, as in the previous analysis flows, you can do One-to-Many or Pairwise Comparisons. Additionally, here you have the option of calculating either the person-level or group-level LSM values or both. For One-to-Many Comparisons, the person-level LSM option displays the LSM for each individual with the average of the rest of the group and the group-level LSM option displays the aggregate results of this calculation for everyone. For Pairwise Comparisons, the person-level LSM option displays the LSM between each possible dyadic combination, while the group-level LSM displays the aggregate results for the same thing.
Analyzing Texts in Different Formats
The LSM tool in LIWC-22 facilitates the calculation of LSM. Depending on the structure of your dataset, there’s three different analysis flow options.
1) When you have individual text files for each speaker…
Use the “Compare 2+ Files” option. Once you select your files for analysis, you have two options. You can do a One-to-Many comparison, which means you calculate the LSM of one file to the average of all the others. Alternatively, you can calculate Pairwise comparisons between all files. If you check “Include Expanded LSM Output” then the results will contain each individual component of LSM (ie. rate at which speakers use each function word category). You can ignore this option if you are only interested in the final LSM score.
One-to-Many comparisons are most useful when you are interested in how each individual fits with the overall group. Pairwise Comparisons are more useful when you are interested in how individuals work with each other.
2) When you have a spreadsheet file with each row denoting a conversation turn or speaker…
Use the “Analyze Spreadsheet” option. This allows you to analyze multiple conversations that are in the same spreadsheet. You indicate which column contains the conversation ID using the “Group ID Column” selection window. You indicate which column identifies speakers using the “Person ID Column” selection window. Finally, you also indicate which column holds your next using the “Text Column” window.
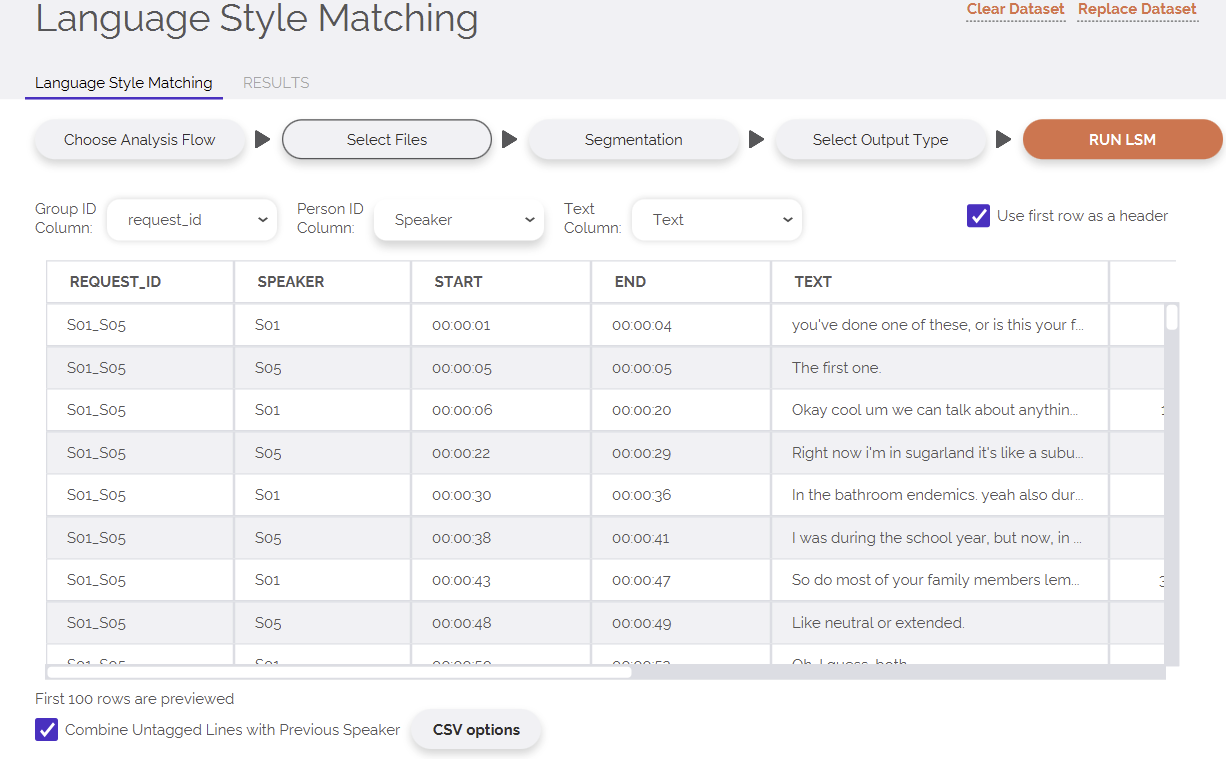
By default, the program will aggregate all text within a conversation by speaker. If you prefer not to do this, there are a number of segmentation options you can select in the segmentation tab, such as splitting text of speakers by word count.
3) When you have transcripts in a document or text file…
Use the “Transcript Files” option. The detect speakers tag will help you identify the speakers in your transcript, as long as you have a common delimiter after each speaker, such as a colon (:). The remaining options are identical to analyzing a spreadsheet file, which is covered in the previous section.
References and Further Reading
- Ireland, M. E., & Pennebaker, J. W. (2010). Language style matching in writing: synchrony in essays, correspondence, and poetry. Journal of Personality and Social Psychology, 99(3), 549–571. https://doi.org/10.1037/a0020386
- Gonzales, A. L., Hancock, J. T., & Pennebaker, J. W. (2010). Language style matching as a predictor of social dynamics in small groups. Communication Research, 37(1), 3–19. https://doi.org/10.1177/0093650209351468